CloudThresholdBook
Chapter 2: The Basics
2.1 Learning Outcomes
By the end of this chapter, the reader should be able to:
- Recognize the underlying technologies that made access to cloud services possible
- Identify the different ways cloud services can be accessed
- Provision and work with basic cloud services
- Navigate the documentation to find answers to their questions
2.2 Introduction
There are many services available by the various providers, and they keep increasing every day. Many services are very similar among the providers, while some are unique. However, all of them build on the core concept of resource virtualization. In section 2.3, we'll introduce the virtualization concept, and in sections 2.4 and 2.5, we'll practice using virtualized resources provided by GCP.
2.3 Resource Virtualization
A computer system's main resources include the processing unit(s), primary and secondary storage, and communication links. A software system like the operating system is needed to manage these hardware resources and make them accessible to high-level applications. The traditional (non-virtualized) approach would be to have the operating system layer tightly coupled with the hardware layer. (Think about how Apple IOS is tightly coupled with Mac and how Windows is tightly coupled with PC). This approach becomes significantly challenging as the scale of the system grows in complexity, accessibility, and diversity of the application.
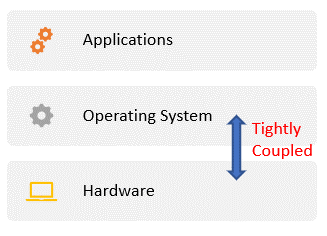
Figure 2.1: OS tightly coupled with hardware
2.3.1 Virtual Machines
You may have encountered the concept of a virtual machine before when you learned Java (or similar) programming language or if you needed to install an application that is not compatible with your operating system (e.g., needed to install an Oracle DBMS on a Mac machine). These are two different types of virtual machines.
A Virtual Machine is a bounded environment that serves as a decoupling layer between two sub-systems. It appears to be a full machine to one sub-system while allowing it controlled access to the other.
With the Java language, the source code is translated into and shipped as an intermediate language (byte-code). To execute the program, it has to run in the JVM (Java Virtual Machine), which translates the byte-code into the language specific to the actual machine it is running on. The JVM appears to be a machine on its own to the program. So, the JVM adds a layer between the program and the actual machine to ensure the independence of the Java program and allow for portability. This is an example of a "process virtual machine".
A Process Virtual Machine is a VM dedicated to a specific process and is terminated after that process is done.
In the case of installing Oracle DBMS (a Windows-compatible software) on Mac, you would need to install a Windows emulator first then install the DBMS on top of it. To the DBMS, the emulator appears to be a Windows machine on its own. This is an example of a "system virtual machine".
A System Virtual Machine is a VM that supports an operating system and all the processes it may include.
2.3.2 Virtualization on the cloud
In the cloud computing context, adding a virtualization layer between the hardware resources and the operating system allows the provider to create multiple system virtual machines with different operating systems on the same physical server, each with controlled access to the actual hardware resources.
2.3.3 Virtual Machine Monitors / Hypervisors
In order to allow the hardware resources of one machine to be shared among multiple virtual machines, a new layer is introduced in the form of software called the hypervisor or the virtual machine monitor (VMM). As shown in the image below, there are three main types of VMMs; they can be installed directly on top of the hardware layer, in which case, it is called bare-metal VMM. Alternatively, it can be installed on top of a host operating system, in which case it would be called a hosted VMM, which may affect the performance since accessing the resources would require going through two additional layers instead of one. However, it provides a level of usability and convenience higher than that of the bare-metal VMM. The hybrid VMM offers the best of both worlds, so you can have a bare-metal VMM that doesn't mandate monopoly over the hardware resources and allows for a host operating system to be installed on the side.
Multiple virtual machines can be installed on top of the hypervisor, each with its own operating system, a guest OS, and its own application. Each of these virtual machines would be completely independent of the other VMs that share the physical resources with it. The VMs are also independent of the actual hardware configuration and specifics; they only need to know how to communicate with the hypervisor.
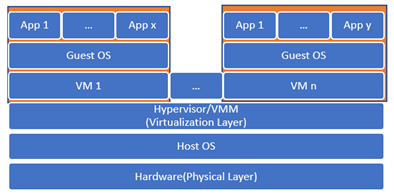
Figure 2.2: Hosted Hypervisor
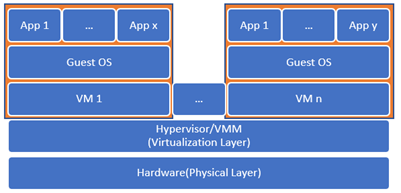
Figure 2.3: Bare-Metal Hypervisor
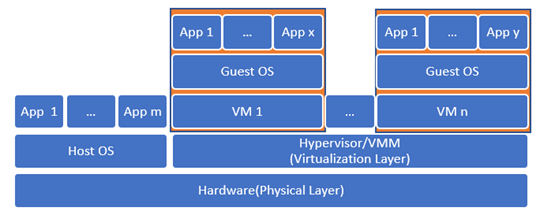
Figure 2.4: Hybrid Hypervisor
2.3.4 Live Migration
Just like how the JVM allows for the interoperability of Java programs, the hypervisor allows for live migration of virtual machines, which made many of the promises of the cloud services possible. Since a virtual machine can run on any physical server as long as it has the same hypervisor installed, mechanisms to ensure high availability, fault tolerance, and load balancing can be put in place.
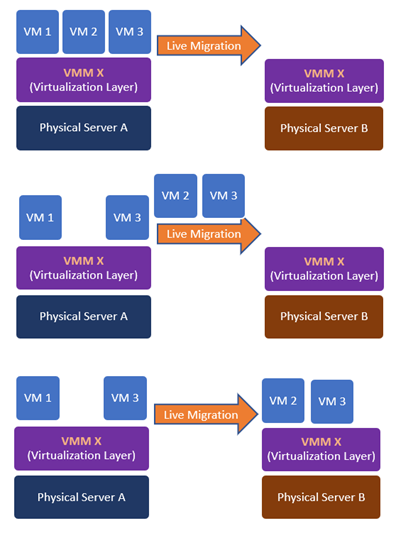
Figure 2.5: Live Migration
2.4 Compute Services
One of the main services offered by a cloud provider is the compute services, through which you can provision a virtual machine on the provider's infrastructure. In the following subsections, we'll practice provisioning and accessing virtual machines on GCP.
2.4.1 Provisioning and accessing a compute engine through the console
- Go to https://cloud.google.com/and log in using your GCP account you created in chapter 1.
- Click on the "Go to console" button
- Click on the hamburger button highlighted by rectangle 1 in the image below to open the navigation menu.
- Under the "Compute" category, click on "Compute Engine".
- If this is the first time for you to use the service, it may take a few seconds to initialize it.
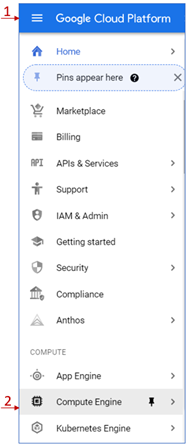
Figure 2.6: Compute Engine Service
- If this is the first instance you create, you'll see the dialog box shown below.
Figure 2.7: VM instances dialog box
- Click on the "Create" button to open the "Create an instance" form.
- Set the name of your instance as well as the region and the zone in which you would like to be provisioned.
- Specify the machine configuration in the section pointed at by arrow 1 in the image below. You can see there are four machine families that you can choose from. If you're planning to use the instance in tasks that include intensive computations, you can select the "Compute-optimized" family. If you're planning to use the instance for tasks that require large memory, you can choose the "Memory-optimized" family. If you don't have any particular optimization needs, you can select the "General-purpose" family.
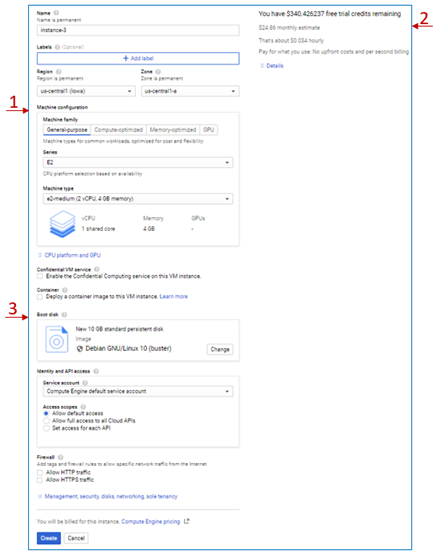
Figure 2.8: VM instance Creation
- You can set a more specific configuration under each family, which will affect the pricing, as you can see on the right side of the page and pointed at by arrow 2.
- Try changing the options selected and see how they affect the pricing.
- For this exercise, we'll leave the default settings.
- Arrow 3 in the image points at the "Boot disk" option. Here you can select the image you would like to install on your VM. This image could include only the operating system or include additional installations like a DBMS, for example. The choice of the image also affects the pricing.
- Click on the change button and select a different image and notice how it affects the price.
- Again, for this exercise, we'll keep the default option.
- We'll discuss some of the other options later in the proper context. However, you can have a brief idea of any option by clicking on the question mark icon beside it.
- Click on the "Create" button and wait for a few seconds while your instance is provisioned.
- Once the instance is ready, you can see it listed under the VM instances with a green checkmark beside its name.

Figure 2.9: VM Instance Created
- You can stop, start, suspend, or delete the instance by checking the box beside the name and clicking on the corresponding button in the top menu. You can also see the same options (and more) by clicking on the three dots button at the end of the row.
- Under the "Connect" column, you can see how you can connect remotely to your instance, for example, using the SSH protocol.
- Click on the SSH button to open web-based command-line access to the instance.
- You can try out some Linux commands just like you would with an actual machine.
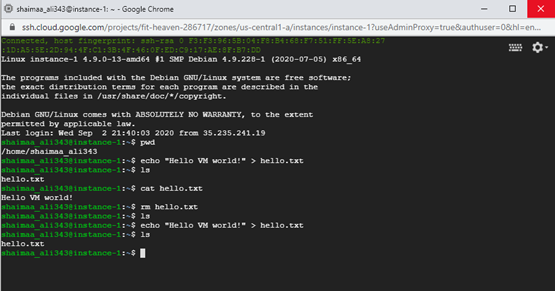
Figure 2.10: SSH access to the VM instance
- Stop the instance you created, just to get into the habit of stopping the services after you are done working with them in order to avoid wasting the resources.
2.4.2 Accessing a compute engine instance through the command line from the local environment
Now we are going to practice accessing the cloud resources through the command-line tool in the local environment we've prepared in chapter 1.
First, we'll access the VM we created in the previous section.
- To list all compute instances available under your account, type the following command in your command-line/terminal session.
> gcloud compute instances list - you should see the list of instances you have under your account listed as shown in the figure below.

Figure 2.11: listing instances through the SDK
- We can see that the instance we created in the previous section is displayed, and its status is "Terminated" as we should expect since we did stop it on the console before.
- Now, we would like to start it in order to access it through the command-line interface; this is not as straightforward as clicking a button as we did on the console, we need to know the command that would allow us to do that, but this is not too hard either, even if you didn't know the exact command, we could use the help available through both the command-line or through GCP documentation.
- To search for help through the command line, we can use the following command: \> gcloud help – \<search-terms\>
So in our case, we would like to search for the command that starts an instance so we can use the following command to look it up: \> gcloud help – start instance
- The result would be a list of commands related to the search terms, the one closest to what we are looking for is shown in the image below.

Figure 2.12: Help search result
The GCP Docs offer a more detailed explanation, so if you go to cloud.google.com, you can see in the upper-right corner a link to the documents highlighted by arrow 1 in the figure below, or you can put your term in the search box highlighted by arrow 2.

Figure 2.13: GCP Docs
In our case, I entered the search terms "gcloud start instance" and the command we are looking for appeared as the first item in the results list.

Figure 2.14: GCP Docs search results
Clicking on it will take us to the command's page with all the details about using it.

Figure 2.14.1: GCP Docs help page
So based on what we've learned, we can issue the following command in order to start the instance:
`> gcloud compute instances start instance-1`
We can see in the image below the output from the start command, and when we list the instances again, we can see that the status is now "Running".

Figure 2.15: Starting an instance through the SDK
Now we need to know how to connect to the instance; you already learned how to find the command if you don't know it, so we'll skip the searching part. The following command allows us to create an ssh connection to the instance named 'instance-1':
`> gcloud compute ssh instance-1`
If this is the first time you run the command, you need to specify the zone where you created the instance. Alternatively, you can set a default project, region, and zone using the command \> gcloud init.
There are several steps executed behind the scenes just by issuing this command. Here's a brief of these steps:
- The credentials you obtained and stored in your local machine when you ran the gcloud login auth command will be retrieved.
- Generate a public/private key pair
- Store the new public key in the VM
- Use the private key generated to connect to the machine.
Now that we're connected to the instance, we can work with it the same way we did using the console by issuing any Linux commands we'd like to get executed, as shown in the figure below.
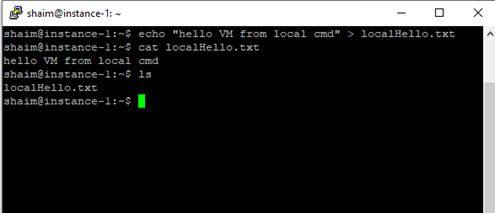
Figure 2.16: Accessing VM instance from the local environment
Notice that the file hello.txt that we created on the instance through the console didn't appear when we issued the 'ls' command. You can also see that the user name as it appears in the prompt is different from the user name shown in the prompt. So you have to be careful if you're accessing the instance using a different environment as it may cause confusion.
However, we're still using the same virtual machine, so both files exist, only in different home folders, since it's a different user.
In the figure below, I changed the directory to go one level up using the command cd .. then issued the command ls to see the content of that directory. We can see that there are two home directories, and both files exist each in its respective directory.
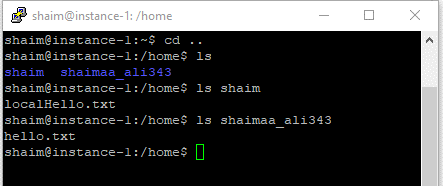
Figure 2.17: Local vs. Console access
Now let's stop the VM through the command line using the following command:
> gcloud compute instances stop instance-1
The figure below shows the output from the 'stop' command as well as the instance's status showing as "Terminated" again after listing the instances.

Figure 2.18: Stopping an instance through the local environment
2.4.3 Accessing compute engines programmatically (using Node.js)
The third way to access your cloud resources is programmatically using the google cloud client library. In chapter 1, we prepared the environment for this type of access by installing Node.js and running the authenticate command. Now, we are going to use a sample script that lists the available instances in a given project.
| We'll use one of the scripts provided as a sample in GCP docs here ([Node.js client library | Google Cloud](https://cloud.google.com/nodejs/docs/reference/compute/latest)). If you click on the link and scroll down to the 'Samples' section, you'll see a list of sample scripts. You can see the code by clicking on the 'source code' link provided. We will be using the 'List All instances' script, so open its source code and have a look at it. |
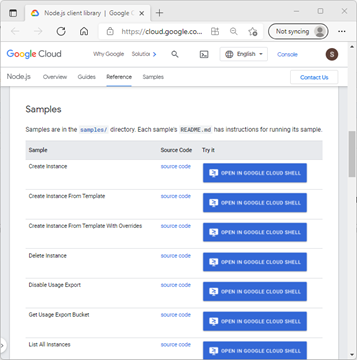
Figure 2.19: Sample JS Scripts
We are going to try to run this script from the local machine. But first, we need to make some preparation. We need to install the npm module of the google client library API that allows us to access the compute instances programmatically. We can do this using the following steps.
- Create a directory for this example and give it a meaningful name (e.g., progAccess)
- From the command-line change directory using the cd command to go to the directory you just created \> cd progAccess
- Run the following npm install command to install the cloud client library progAccess\> npm install @google-cloud/compute (if you're running this command on a Linux machine, you may need to add sudo at the beginning)
- Create a text file with the name listAllVMs.js and copy the sample script into it.
- The script expects the project id to be sent as an argument, so in order to execute it, we need to issue the command progAccess\> node listAllVMs.js \<project-id\>
The figure below demonstrates how I ran the command and its output.

Figure 2.20: VM instances accessed and listed programmatically
Please note that Node.js is not the only way to access GCP services programmatically. You can see a list of client libraries for other languages here, and you can find the documentation for the compute engine Node.js client here.
In this section, we created a few virtual machines, and we learned that a virtual machine allows us access to virtualized portions of the physical resources. If you go to the dashboard of the console and if you didn't change the default settings of the dashboard, you should be able to see the compute engine CPU utilization card similar to the one shown in the figure below. But the CPU is not the only virtualized resource accessible through the VM. Storage resources are essential for the VM, just like they are essential for any physical machine. Can you imagine buying a computer that doesn't have a hard desk? In the next section, we'll learn how to work with the basic storage services provided by GCP.
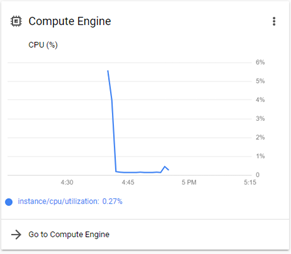
Figure 2.21: CPU utilization card
2.5 Storage Services
There are three main types of storage services, block storage, object storage, and file storage. The block storage is the most basic of them, and it's basically a virtual hard disk in which the data are stored in raw blocks without any structure or format associated with it unless through a file system that's part of the operating system.
Figure 2.22 demonstrates how the data are stored in numbered blocks.
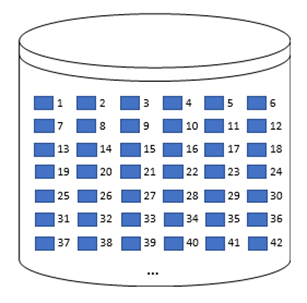
Figure 2.22: Block Storage
Figure 2.23 shows how the file system determines which of these blocks belong together to form a file/directory structure and associate metadata to them (e.g., file name, date updated, etc.). Cloud file storage services like Filestore on GCP allow us to create a network file server that's independent of the operating system and can be shared among multiple VMs.
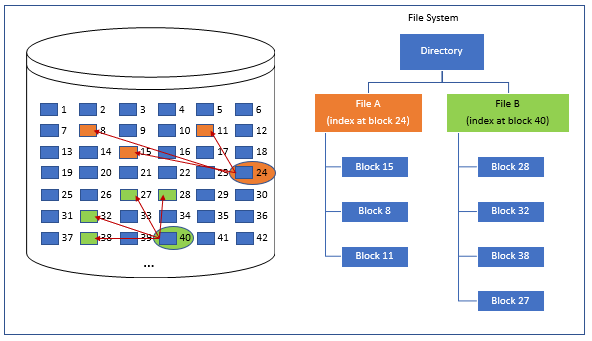
Figure 2.23: File Storage
Object storage allows for offering the storage service without needing a server since the data and the metadata are encapsulated in objects stored in buckets. The buckets are accessible directly using web protocols such as HTTP. So, a bucket is capable of receiving an HTTP request, and it sends the requested data in an HTTP response, which makes it possible to use the bucket as a basic web server that serves with static content only.
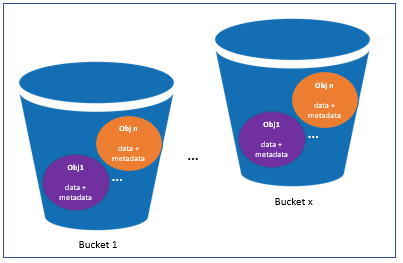
Figure 2.24: Object Storage [1]
If you go to GCP's console and open the side navigation menu, you'll see under the 'Storage' category there are three services. The "Data Transfer" service is used to transfer the data to and from cloud storage. The 'Filestore' is GCP's file storage, and 'Storage' is GCP's object storage.

Figure 2.25: GCP's Storage services
The block storage is not listed here because it's not accessible unless through a compute instance. It's listed under the sub-menu of the 'Compute Engine' service with the name 'Disks' as shown in the figure below.
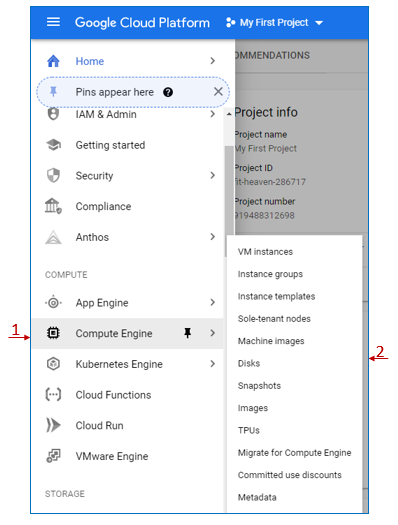
Figure 2.26: GCP Compute Engine Storage
If you click on the 'Disks' menu item, you'll see a list of the disks you created. The image below shows the two disks that were created as part of the two instances we provisioned before. Each disk takes the same name as the VM instance it's used by, as you can see by looking at the 'Name' and 'In use by' columns.
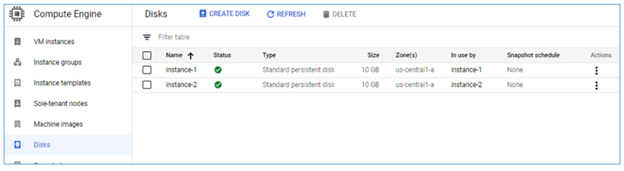
Figure 2.27: Disks created for the compute instances
We can also create a disk independent from any VM by clicking on the 'Create Disk' button highlighted by the red rectangle. This disk can be treated like a virtual external hard drive that we can attach to any VM instance. In fact, it can be accessed by multiple instances in a read-only fashion, but it can be used for writing by only one VM.
Let's start by creating the disk by clicking on the 'Create Disk' button, which opens the "Create Disk" form that allows us to make the settings for the newly created disk. For the sake of this example, we'll leave the default settings, including the name, which is 'disk-1'. Before we click create, take a moment and look at the different settings in the form, try to understand one of them, and answer the corresponding review question.
Now click on the 'Create' button and give it a few moments to be provisioned. 'disk-1' should appear on the list with the size 100 GB (the default) as opposed to the 10 GB of the two other disks as shown in the figure below. Since this disk is unattached to any instance, its 'In use by' value is empty.
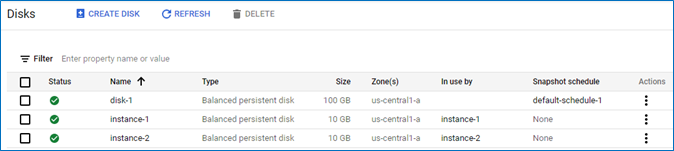
Figure 2.28: Newly created disk shown in the disks list
Let's attach disk-1 to VM instance-1 for read and write, so click on VM instances in the side menu, then click on instance-1 and scroll down in the VM instance details page to see the 'Boot disk' section that displays the information about the disk that was created for this instance highlighted by arrow 1 in the figure below.
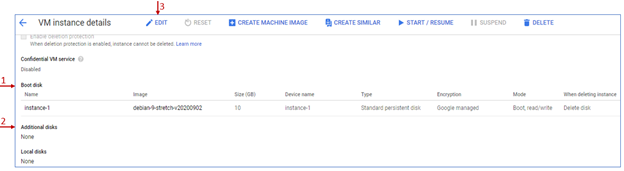
Figure 2.29: Disks sections in the VM instance details page
Arrow 2 in the figure highlights the 'Additional disks' section, which shows that no additional disks are attached to this instance yet. Click on the 'Edit' button highlighted by arrow 3 to be able to make changes to the instance.
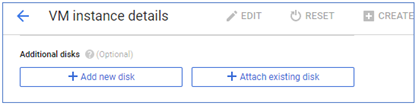
Figure 2.30: Attach existing disk
Scroll down to the "Additional disks" section and click on the "Attach existing disk" button. In the existing form shown below, choose 'disk-1' from the drop-down menu, keep the default 'Read/write' mode and click 'Done'.
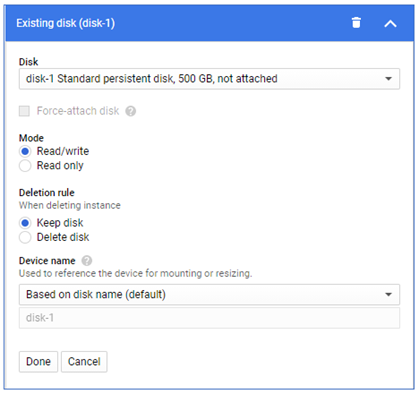
Figure 2.31: Additional disk settings
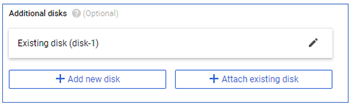
Figure2.32: New disk added to a VM instance
Scroll down and click on the 'Save' button to save the changes made to the VM.
Now, let's go back to the instances list and connect to instance-1 via SSH. We can see all disks attached to this instance by issuing the command$ ls -l /dev/disk/by-id . You can see that disk-1 is listed with the alias google-disk-1, as shown in the image below.
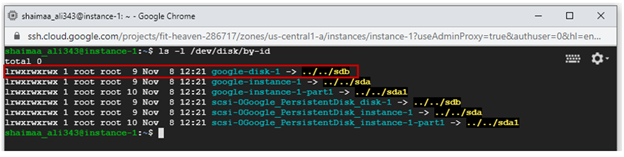
Figure 2.33: Additional disk listed within the VM instance
Two steps remain in order to be able to access this disk. It needs to be formatted to create its own file system, then mounted to the instance's file system.
The command below uses mkfs tool (short for make file system) to format a device specified by the \<DVICE_ID\> with ext4 file system. (Please note that this command will delete any contents on the disk, so be careful when you specify the disk id)
$ sudo mkfs.ext4 -m 0 -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/disk/by-id/<DEVICE_ID>
The image below shows the output of formatting the disk with the id 'google-disk-1'.
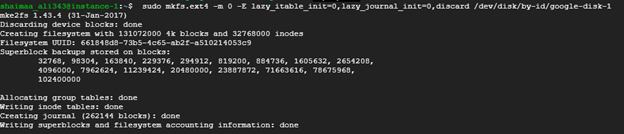
Figure 2.34: Formatting the additional disk using mkfs tool
In order to mount that disk to the instance, we need to create a directory under the path /mnt/disks then use this directory as the mounting point for the disk. The following command would create that directory and the parent directories if they didn't already exist.
$ sudo mkdir -p /mnt/disks/<mount-dir-name>
Since we're going to use this disk for writing, we need to change the permissions to allow writing for all users with the following command:
$ sudo chmod a+w /mnt/disks/<mount-dir-name>
The following command uses the mount tool to (not surprisingly) mount the additional disk using the directory created for it.
$ sudo mount -o discard,defaults /dev/disk/by-id/<device-id> /mnt/disks/<mount-dir-name>
Executing the previous two commands after replacing the \<mount-dir-name\> with the 'additional-disk-1' and the device-id with 'google-disk-1' and we are ready to use the device.
Remember the two files that we created at the beginning of the chapter? We'll copy these two files to the new disk then will display the contents of the new copies as shown in the image below:
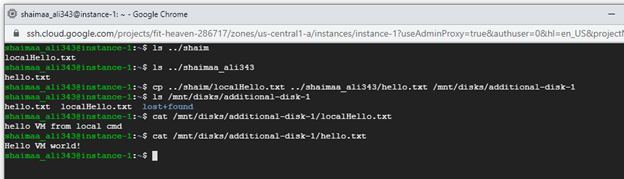
Figure 2.35: Using the additional disk for reading and writing
So, we were able to use the disk for both reading and writing, and if we go back to the disks list, we'll see that this disk is now in use by 'instance-1'.
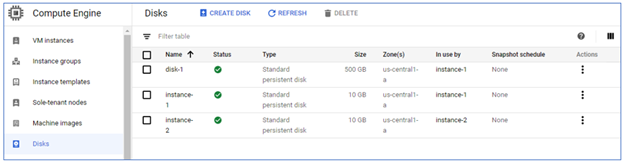
Figure 2.36: The Additional Disk 'In use by' instance-1
2.6 Summary
In this chapter, we discussed the following:
- The resource virtualization technology enabled the access of shared resources provided through cloud services.
- Three different ways that we can work with GCP cloud resources, namely, the console web interface, the local command-line interface using the SDK, and programmatically using client libraries.
- Provision and access virtualized compute resources by creating VM instances.
- Provision and access virtualized storage resources by creating virtual disk drives.
Relevant lab(s) on Qwicklabs
- Hosting a Web App on Google Cloud Using Compute Engine
Image Credits
[1] Image courtesy of Amazon Web Services LLC in the Public Domain , modified by the author using PowerPoint.
{kind=link}
[GCP Screenshots] "Google and the Google logo are registered trademarks of Google LLC, used with permission."
Unless otherwise stated, all images in this chapter were created by the author Shaimaa Ali using either MS PowerPoint or MS Visio or both.
© Shaimaa Ali 2022